
Калькулятор мер
хомер поклажа осла
Основой мер сыпучих и жидкостей является хомер, хотя сам не является мерой для жидкостей. Самая большая мера для жидкостей — бат — в 10 раз меньше хомера. Выглядит довольно странно, что за эталон принимается не самая малая мера (как, например, гера — зёрнышко), а самая большая. Громоздкой меркой сложнее определить точную меру. Просто в этом Господь позволил людям иметь гибкость. Чсл 11:32И встал народ, и весь тот день, и всю ночь, и весь следующий день собирали перепелов; и кто мало собрал, тот собрал 10 хомеров...
10 хомеров = 1800 кг = 10 поклаж осла, человек мог это принести за 70 (!) раз. Ос 31:2И приобрёл я её себе за 15 серебряников и за 1,5 хомера ячменя. 1,5 хомера — где-то 270 кг ячменя или 5,5 мешков (по 50 кг). кор
3Цар 4:2Продовольствие Соломона на каждый день составляли: 30 коров пшеничной муки, 5,4 тонн
Всего около 16 тонн муки в день. Это сколько ж человек нужно, чтобы съесть всё это? Теперь для нас сколько-то понятно, какую бюрократическую систему развил Соломон и почему народ хотел снижения налогов. сата
Меня удивили некоторые вещи тех лет. Зарплата за день составляла драхму, на что семья могла прожить 3 дня, а вместе с тем самой ходовой монетой был тетрадрахм (4 драхмы). 1Цар 25:18Тогда Авигея взяла: 200 (!) хлебов, и 2 меха с вином, и 5 овец приготовленных, и 5 мер (в оригинале «сат»), и 100 (!) связок изюму, и 200 связок смокв, и навьючила на ослов.
Здесь речь идёт либо о большом количестве (100, 200), либо о крупных вещах (мех вина, овца). Сата относилась к крупным мерам. гомор суточный паёк манны в пустыне
Исх 16:36А гомор есть десятая часть ефы. (1/3 саты). В пустыне люди питались только манной и потребляли её по гомору в день. Саты хватало на троих. Но человек ест не только хлеб. Скажем, дневной паёк римской армии составлял 850 г пшеницы, сало и соль, иногда мясо и овощи. Итак, чем же потчевал гостей Авраам? Если бы он дал им только хлеба, то им бы и саты вполне хватило. Авраам дал им три. Кроме того, он подал на стол масло, молоко и телёнка. Самые голодные три человека и за день не съели бы всего этого. Другими словами «стол ломился от еды». И было чего дать им с собой в дорогу.
Дело в том, что, подобно им, Авраам сам был пришельцем в этой земле, подобно им. Но Ханаанская земля встретила его голодом, и он вынужден был искать приюта в соседней стране. Мт 13:33женщина замесила 3 меры муки (в оригинале «саты») 1 сата — это количество муки для семьи на неделю. 3 саты — это около 18 кг. Где же замешивают такое количество? Обычная посуда слишком мала для этого, кто-то использует для таких дел корыто. То есть в притче говорится о максимально возможном представить для хозяйки количестве муки, и о закваске, ничтожно малого количества того же самого теста, только вскисшего.То есть, пусть Мончегорск большой, но немногие горящие верующие способны сделать так, чтобы «вскисло всё». ζυμη — квасить, от ζεω — кипеть. каб самая малая мера сыпучих тел
Самая малая мера сыпучих тел. Если мерят кабом, значит голодный год. Сегодня евреи говоря «каб», имеют в виду ничтожно малую меру. Что-то вроде того, как мы употребляем слово «лепта». В Библии встречается всего 1 раз. 4Цар 6:25 ослиная голова за 80 шекелей, 1/4 каба (250 г) голубиного помёта — 5 шекелей. Помёт являлся топливом. И когда мы измеряем дрова самой малой мерой? 4Цар 7:1 сата (6 кг) лучшей муки — 1 шекель, 2 саты (12 кг) ячменя — 1 шекель. Только зная меру веса можно понимать разницу. ефа мера египетского происхождения
обычная мера на рынке — ефа (3 саты или 18 кг), чтобы 2 раза не ходить. Вт 25:13-15 гиря у тебя должна быть точная и правильная, и ефа у тебя должна быть точная и правильная. Самой обычной мерой на рынке была ефа (3 саты или 18 кг), «чтобы 2 раза не ходить». Пр 20:10 Неодинаковые весы, неодинаковая мера (в оригинале «ефа»), то и другое мерзость перед Господом. Мих 6:10 …и уменьшенная мера (в оригинале «ефа»), отвратительна? Почему старались сделать ефу поменьше? Ведь этой мерой отдаёшь. Но Иисус учил нас давать мерой полною, утрясённою, переполненною. гин мера египетского происхождения
Лев 19:36да будут у тебя весы верные, гири верные, ефа верная и гин верный. Ефой мерили хлеб, гином вино и елей. Лев 23:13 гин вина фунт
Ин 19:39Никодим … принёс состав из смирны и алоя, литр около ста. модий хлебная мера
Встречается в Библии только в одной притче (Мт 5:15, Мк 4:21, Лк 11:33). Мт 5:15И зажегши свечу, не ставят её под СОСУДОМ (в оригинале «модий»), но на подсвечнике, и светит всем в доме. хиникс суточный паёк
От 6:5-6И когда он снял 3-ю печать, я слышал 3-е животное, говорящее: иди и смотри. Я взглянул, и вот, конь вороной, и на нём всадник, имеющий МЕРУ в руке своей. И слышал я голос посреди 4-х животных, говорящий: ХИНИКС пшеницы за динарий, и 3 ХИНИКСА ячменя за динарий; 2218ζυγος мера — коромысло весов, ярмо [от впрягать, связывать].
В отличие от истории из 4-й Царств, здесь не непосильно высокая цена, а то, что мы называем «от зарплаты до зарплаты». паёк паёк римской армии
| БОЖЬЯ СИСТЕМА ВРЕМЯ СЕЗОНЫ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


 На эту сумму семья могла прожить 12 дней. Это указывает на иной стиль жизни. Мы сегодня раз в месяц затовариваемся, а потом что-то по мелочам подкупаем: хлеб, шоколад, жевательную резинку… В те времена таких мелочей не было, и всё закупалось преимущественно оптом. Потому в ходу больше были крупные суммы и большие меры (ефа, сата).
На эту сумму семья могла прожить 12 дней. Это указывает на иной стиль жизни. Мы сегодня раз в месяц затовариваемся, а потом что-то по мелочам подкупаем: хлеб, шоколад, жевательную резинку… В те времена таких мелочей не было, и всё закупалось преимущественно оптом. Потому в ходу больше были крупные суммы и большие меры (ефа, сата).
 Авраам знал, что значит быть в шкуре этих людей. И сейчас ему доставляло удовольствие дать им то, о чём он мечтал в то время.
Авраам знал, что значит быть в шкуре этих людей. И сейчас ему доставляло удовольствие дать им то, о чём он мечтал в то время.



 Денарий — плата за день работы, а хиникс — норма на день хлеба, причём на одного человека, а не на семью. Такая ситуация может продолжаться сколько угодно долго, то есть «кандалы». «От зарплаты до зарплаты» и «каждый сам за себя».
Денарий — плата за день работы, а хиникс — норма на день хлеба, причём на одного человека, а не на семью. Такая ситуация может продолжаться сколько угодно долго, то есть «кандалы». «От зарплаты до зарплаты» и «каждый сам за себя».
Меры веса и длины — ОНЛАЙН-БИБЛИОТЕКА Сторожевой башни
МЕРЫ ВЕСА И ДЛИНЫ
Установить приблизительно, чему были равны различные меры веса и длины, которые использовали евреи, позволяют археологические находки, сама Библия и другие древние труды.
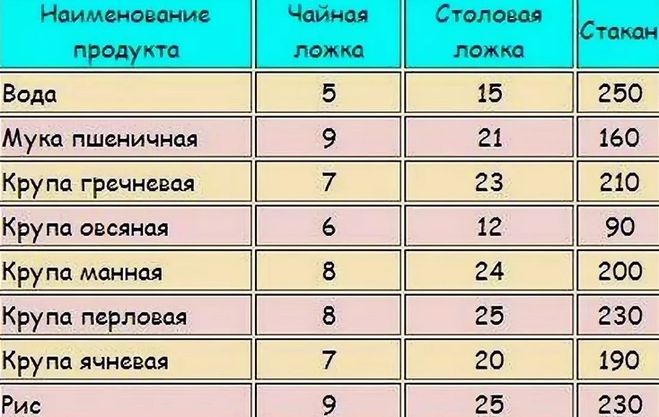
Меры длины. У евреев меры длины, очевидно, были связаны с телом человека. Поскольку можно установить соотношение длины или ширины одной части тела к другой, можно также установить соответствие одной меры длины к другой, а на основании археологических находок, указывающих на то, что локоть равен примерно 44,5 см, меры длины, упомянутые в Библии, можно примерно отразить в современных единицах измерения. (См. ЛОКОТЬ.) В нижеприведенной таблице указано соотношение еврейских мер длины и даны их современные эквиваленты.
(См. ЛОКОТЬ.) В нижеприведенной таблице указано соотношение еврейских мер длины и даны их современные эквиваленты.
Меры длины
—
—
Современный эквивалент
1 палец
= 1⁄4 ладони
1,85 см
1 ладонь
= 4 пальца
7,4 см
1 пядь
= 3 ладони
22,2 см
1 локоть
= 2 пяди
44,5 см
1 длинный локоть*
= 7 ладоней
51,8 см
1 короткий локоть
—
38 см
1 трость
= 6 локтей
2,67 м
1 длинная трость
= 6 длинных локтей
3,11 м
* Возм. , то же, что и локоть «по прежней мере» во 2Лт 3:3.
, то же, что и локоть «по прежней мере» во 2Лт 3:3.
Существуют разные мнения по поводу меры длины, обозначенной еврейским словом го́мед, которое встречается лишь в Судей 3:16 в связи с длиной меча Аода. В ряде переводов это слово передано как «локоть» (СП, НМ, ПАМ, СоП, Шб). По мнению некоторых ученых, го́мед обозначает короткий локоть, длина которого приблизительно соответствует расстоянию от локтя до кисти, сжатой в кулак, то есть около 38 см.
В Писании также упоминаются такие меры длины, как сажень (1,8 м), ста́дион, или стадий (185 м), и миля, вероятно римская миля (1479,5 м). В Библии расстояние часто указывается в днях пути (Бт 30:36; Исх 3:18, сноска; Чс 11:31; 1Цр 19:4). Один день пути, возможно, равнялся 32 км и более, а субботний путь, по-видимому, был равен примерно 1 км (Мф 24:20; Де 1:12; см. МИЛЯ; ПУТЬ; САЖЕНЬ; СТАДИЙ).
Меры объема. Судя по фрагментам кувшинов, на которых написано древнееврейское слово «бат», бат составлял около 22 л. В таблицах, приведенных ниже, меры сыпучих тел и меры жидкостей приведены в соотношении с батом. Соотношения мер, не указанные в Библии, выводятся на основании других древних трудов. (См. БАТ; ГИН; ГОМОР; КАБ; КОР; ЛОГ; САТА; ХОМЕР.)
В таблицах, приведенных ниже, меры сыпучих тел и меры жидкостей приведены в соотношении с батом. Соотношения мер, не указанные в Библии, выводятся на основании других древних трудов. (См. БАТ; ГИН; ГОМОР; КАБ; КОР; ЛОГ; САТА; ХОМЕР.)
Меры сыпучих тел
—
—
Современный эквивалент
1 каб
= 4 лога
1,22 л
1 гомор
= 14⁄5 каба
2,2 л
1 сата
= 31⁄3 гомора
7,33 л
1 ефа
= 3 саты
22 л
1 хомер
= 10 еф
220 л
Меры жидкостей
—
—
Современный эквивалент
1 лог
= 1⁄4 каба
0,31 л
1 каб
= 4 лога
1,22 л
1 гин
= 3 каба
3,67 л
1 бат
= 6 гинов
22 л
1 кор
= 10 батов
220 л
Другие меры сыпучих тел и жидкостей. Под еврейским словом иссаро́н, означающим «десятая часть», часто подразумевается десятая часть ефы (Исх 29:40; Лв 14:10; 23:13, 17; Чс 15:4). Согласно Таргуму Ионафана, «шесть мер ячменя [букв. «шесть ячменя»]», упомянутые в Руфи 3:15,— это шесть сат. Судя по Мишне и Вульгате, еврейское слово ле́тех обозначает половину хомера (Ос 3:2, СП, НМ, Тх, также СоП, сноска). По мнению некоторых ученых, меры, обозначавшиеся греческими словами метрете́с (встречается во мн. ч. в Ин 2:6 и переводится как «меры жидкости») и ба́тос (употребляется во мн. ч. в Лк 16:6), соответствовали еврейскому бату. Считается, что греческая мера хо́йникс (хиникс) составляет чуть больше литра (Отк 6:5, 6).
Под еврейским словом иссаро́н, означающим «десятая часть», часто подразумевается десятая часть ефы (Исх 29:40; Лв 14:10; 23:13, 17; Чс 15:4). Согласно Таргуму Ионафана, «шесть мер ячменя [букв. «шесть ячменя»]», упомянутые в Руфи 3:15,— это шесть сат. Судя по Мишне и Вульгате, еврейское слово ле́тех обозначает половину хомера (Ос 3:2, СП, НМ, Тх, также СоП, сноска). По мнению некоторых ученых, меры, обозначавшиеся греческими словами метрете́с (встречается во мн. ч. в Ин 2:6 и переводится как «меры жидкости») и ба́тос (употребляется во мн. ч. в Лк 16:6), соответствовали еврейскому бату. Считается, что греческая мера хо́йникс (хиникс) составляет чуть больше литра (Отк 6:5, 6).
Меры веса. Судя по археологическим находкам, сикль равнялся примерно 11,4 г. На основании этого в приведенной ниже таблице дается соотношение еврейских мер веса и приводятся их приблизительные современные эквиваленты.
Меры веса
—
—
Современный эквивалент
1 гера
= 1⁄20 сикля
0,57 г
1 бека (полсикля)
= 10 гер
5,7 г
1 сикль
= 2 беки
11,4 г
1 мина (мане)
= 50 сиклей
570 г
1 талант
= 60 мин
34,2 кг
Принято считать, что мера, обозначавшаяся греческим словом ли́тра, соответствовала римскому фунту (327 г). Мина, упомянутая в Христианских Греческих Писаниях, равнялась 100 драхмам. (См. ДРАХМА.) В таком случае вес греческой мины составлял 340 г, а вес греческого таланта — 20,4 кг. (См. ДЕНЬГИ; МИНА; СИКЛЬ; ТАЛАНТ.)
Мина, упомянутая в Христианских Греческих Писаниях, равнялась 100 драхмам. (См. ДРАХМА.) В таком случае вес греческой мины составлял 340 г, а вес греческого таланта — 20,4 кг. (См. ДЕНЬГИ; МИНА; СИКЛЬ; ТАЛАНТ.)
Площадь. Размер участка земли евреи определяли либо по тому, сколько семян можно на нем посеять (Лв 27:16; 1Цр 18:32), либо по тому, сколько может вспахать за день пара быков (1См 14:14, сноска).
[Иллюстрация]
Найденный в Лахисе набор гирь, каждая весом в разное количество сиклей
Исследовательский факторный анализ (EFA) в AMOS
Я хотел бы провести исследовательский факторный анализ (EFA) в AMOS. Согласно недавней статье Hessen et al. (2006), EFA не будет идентифицирован в рамках подтверждающего факторного анализа (CFA), если мы не ограничим лямбда-транспонированную * лямбда-матрицу диагональностью. (См. Hessen на стр. 237. Лямбда — это матрица факторной нагрузки. ) Можно ли применить это ограничение в AMOS? Если нет, то можно ли определить модель ОДВ в AMOS?
Гессен, Д. Дж., Долан, К. В., и Вихертс, Дж. М. (2006) Мультигрупповая модель общего фактора с минимальными ограничениями уникальности и способностью обнаруживать единообразное смещение. Прикладное психологическое измерение, 30 (3), 233-246
) Можно ли применить это ограничение в AMOS? Если нет, то можно ли определить модель ОДВ в AMOS?
Гессен, Д. Дж., Долан, К. В., и Вихертс, Дж. М. (2006) Мультигрупповая модель общего фактора с минимальными ограничениями уникальности и способностью обнаруживать единообразное смещение. Прикладное психологическое измерение, 30 (3), 233-246
В Amos нет способа ограничить Lambda-transposed*Lambda диагональю, но на самом деле это не является необходимым условием для идентификации параметра. Существует более одного способа сделать модель идентифицированной. Одна из альтернатив ограничениям в статье Гессена состоит в том, чтобы зафиксировать факторные дисперсии на уровне 1 и потребовать, чтобы (1) один конкретный показатель зависел только от фактора 1, (2) другой конкретный показатель зависел только от фактора 2 и так далее. Это можно сделать в Амосе.
Чтобы проиллюстрировать спецификацию модели EFA в AMOS, рассмотрите пример 8 в Руководстве пользователя AMOS. Этот пример в Руководстве демонстрирует подтверждающий факторный анализ (CFA), но мы можем преобразовать модель в модель EFA, изменив несколько параметров.
1. В AMOS откройте файл проекта Ex08.amw. Этот файл хранится в папке Examples папки, в которой был установлен AMOS. В этом примере используется файл данных Grnt_fem.sav, который также хранится в каталоге примеров AMOS.
2. В модели CFA примера 8 скрытая переменная SPATIAL указывается наблюдаемыми переменными VISPERC, CUBES и LOZENGES, а скрытая переменная VERBAL указывается наблюдаемыми переменными PARAGRAP, SENTENCE и WORDMEAN. В модели CFA вес регрессии от SPATIAL к VISPERC фиксируется равным 1 для масштабирования скрытой переменной. Вес регрессии от VERBAL до PARAGRAP также фиксируется равным 1. Освободите каждое из этих ограничений, щелкнув правой кнопкой мыши фиксированный вес регрессии и выбрав «Свойства объекта» во всплывающем меню. На вкладке «Параметры» удалите значение 1 из поля «Регрессия» и закройте диалоговое окно.
3. Добавьте стрелки регрессии от SPATIAL к каждому из PARAGRAP и SENTENCE. Аналогичным образом добавьте стрелки регрессии от VERBAL к каждому из VISPERC и CUBES.
4. Зафиксируйте отклонения ПРОСТРАНСТВЕННЫХ и ВЕРБАЛЬНЫХ значений на 1. Для каждой из этих скрытых переменных щелкните правой кнопкой мыши эллипс и выберите «Свойства объекта» во всплывающем меню. В теге Parameters введите 1 в поле Variance и закройте диалоговое окно Object Properties.
Чтобы проиллюстрировать альтернативную модель ОДВ, вы могли бы создать одну из двух скрытых переменных, определяемых всеми шестью наблюдаемыми переменными На шаге 3 выше. Например, вы могли бы нарисовать регрессионную стрелку от ПРОСТРАНСТВЕННОГО к СРЕДНЕМУ СЛОВУ, а также добавить стрелки от ПРОСТРАНСТВЕННОГО к АБЗАЦУ и ПРЕДЛОЖЕНИЮ. без добавления стрелки VERBAL->LOZENGES. Чтобы идентифицировать эту модель, вам нужно убрать двунаправленную стрелку ковариации между ПРОСТРАНСТВЕННЫМ и ВЕРБАЛЬНЫМ, чтобы две скрытые переменные стали ортогональными
[{«Продукт»:{«код»:»SSLVC7″,»метка»:»IBM SPSS Amos»},»Бизнес-подразделение»:{«код»:»BU059″,»метка»:»IBM Software w \/o TPS»},»Компонент»:»Неприменимо»,»Платформа»:[{«код»:»PF025″,»метка»:»Независимая от платформы»}],»Версия»:»Неприменимо», «Издание»:»»,»Направление деятельности»:{«код»:»LOB10″,»метка»:»Данные и ИИ»}}]
Структурные модели (EFA, CFA, SEM, .
 ..) • параметры
..) • параметры Источник: виньетки/efa_cfa.Rmd
efa_cfa.Rmd
Как выполнить факторный анализ (FA)
Различие между PCA и EFA может быть довольно сложно понять интуитивно. понять, как их вывод очень знаком. Идея состоит в том, что PCA направлена на извлечение максимально возможной дисперсии из всех переменных набора данных, в то время как EFA направлен на создание согласованных факторов из набора данных без отчаянно пытаясь представить все переменные.
Вот почему PCA популярен для уменьшения количества функций, так как он пытается наилучшим образом представляют дисперсию, содержащуюся в исходных данных, сводя к минимуму потеря информации. С другой стороны, EFA обычно находится в контекст исследования скрытых измерений, которые могут быть скрыты в наблюдаемые переменные, не обязательно стремясь представить все набор данных.
Чтобы проиллюстрировать EFA, давайте воспользуемся Международным пулом индивидуальных характеристик. данные доступны в
данные доступны в psych упаковка. Он включает в себя 25 элементов самоотчета о личности. Авторы построили
эти предметы после больших 5 личности
структура.
Структура факторов (Сферичность и КМО)
Первый шаг — проверить, подходит ли набор данных для проведения факторный анализ. Есть два
Тест сферичности Бартлетта : Этот тест существенно ли отличается матрица (корреляций) от единичная матрица. Тест обеспечивает вероятность того, что корреляция матрица имеет значительные корреляции по крайней мере между некоторыми переменными в наборе данных, необходимое условие для работы факторного анализа. В других словами, прежде чем приступить к факторному анализу, нужно проверить, Критерий сферичности Бартлетта имеет большое значение.
Кайзер, Мейер, Олкин (КМО) Мера адекватности выборки (MSA) : Этот тест был введен Кайзером (1970) как мера Адекватности выборки (MSA), позже модифицированной Кайзером и Райсом (1974).
 Статистика Кайзера-Мейера-Олкина (КМО), которая может варьироваться от 0 до 1,
указывает степень предсказания каждой переменной в наборе
без ошибок по другим переменным. Значение 0 указывает, что
сумма частных корреляций велика по сравнению с суммой корреляций,
что указывает на то, что факторный анализ, вероятно, неуместен. Значение КМО
близкое к 1 указывает на то, что сумма частных корреляций невелика
относительно суммы корреляций, поэтому факторный анализ должен давать
явные и надежные факторы.
Статистика Кайзера-Мейера-Олкина (КМО), которая может варьироваться от 0 до 1,
указывает степень предсказания каждой переменной в наборе
без ошибок по другим переменным. Значение 0 указывает, что
сумма частных корреляций велика по сравнению с суммой корреляций,
что указывает на то, что факторный анализ, вероятно, неуместен. Значение КМО
близкое к 1 указывает на то, что сумма частных корреляций невелика
относительно суммы корреляций, поэтому факторный анализ должен давать
явные и надежные факторы.
Оба теста можно выполнить с помощью функция performance::check_factorstructure() . Сначала мы
настроить данные.
библиотека (параметры) библиотека (псих) # Загружаем данные data <- psych::bfi[ 1:25] # Выбрать только 25 первых столбцов, соответствующих элементам data <- na.omit(data) # удаляем пропущенные значения
Далее проверяем test, подходит ли набор данных для проведения факторный анализ.
библиотека(производительность) # Проверить факторную структуру производительность::check_factorstructure(данные) #> # Подходят ли данные для факторного анализа? #> #> - KMO: Мера Кайзера, Мейера, Олкина (KMO) адекватности выборки предполагает, что данные кажутся подходящими для факторного анализа (KMO = 0,85).#> - Сферичность: критерий сферичности Бартлетта предполагает наличие достаточной значимой корреляции данных для факторного анализа (Chisq(300) = 18146,07, p < 0,001).
Исследовательский факторный анализ (EFA)
Теперь, когда мы уверены, что наш набор данных подходит, мы исследовать факторную структуру, состоящую из 5 скрытых переменных, соответствующих Авторы статей о личности.
# Подходит для EFA efa <- psych::fa(data, nfactors = 5) %>% model_parameters (сортировка = ИСТИНА, порог = «максимум») эфа #> # Чередующиеся нагрузки из факторного анализа (облимин-ротация) #> #> Переменная | МР2 | МР1 | МР3 | МР5 | МР4 | Сложность | Уникальность #> ------------------------------------------------ ------------------------- #> N1 | 0,83 | | | | | 1.07 | 0,32 #> N2 | 0,78 | | | | | 1.03 | 0,39#> N3 | 0,70 | | | | | 1.08 | 0,46 #> N5 | 0,48 | | | | | 2,00 | 0,65 #> N4 | 0,47 | | | | | 2.33 | 0,49 #> Е2 | | 0,67 | | | | 1.08 | 0,45 #> Е4 | | -0,59 | | | | 1,52 | 0,46 #> Е1 | | 0,55 | | | | 1,22 | 0,65 #> Е5 | | -0,42 | | | | 2,68 | 0,59#> Е3 | | -0,41 | | | | 2,65 | 0,56 #> С2 | | | 0,67 | | | 1.18 | 0,55 #> С4 | | | -0,64 | | | 1.13 | 0,52 #> С3 | | | 0,57 | | | 1.10 | 0,68 #> С5 | | | -0,56 | | | 1,41 | 0,56 #> С1 | | | 0,55 | | | 1.20 | 0,65 #> А3 | | | | 0,68 | | 1.06 | 0,46 #> А2 | | | | 0,66 | | 1.03 | 0,54 #> А5 | | | | 0,54 | | 1,48 | 0,53 #> А4 | | | | 0,45 | | 1,74 | 0,70 #> А1 | | | | -0,44 | | 1,88 | 0,80 #> О3 | | | | | 0,62 | 1.16 | 0,53 #> О5 | | | | | -0,54 | 1.21 | 0,70 #> О1 | | | | | 0,52 | 1.10 | 0,68 #> О2 | | | | | -0,47 | 1,68 | 0,73 #> О4 | | | | | 0,36 | 2,65 | 0,75 #> #> На 5 скрытых факторов (вращение облимина) приходится 42,36% общей дисперсии исходных данных (MR2 = 10,31%, MR1 = 8,83%, MR3 = 8,39).%, СО5 = 8,29%, СО4 = 6,55%).
Как мы видим, 25 элементов хорошо распределены по 5 скрытым факторам, знаменитый большой 5 . Теперь на основе этой модели мы можем предсказать баллы для каждого человека для этих новых переменных:
# давайте посмотрим только на первые пять человек
head(predict(efa, names = c("Нейротизм", "Сознательность", "Экстраверсия", "Приятность", "Открытость")), 5)
#> Нейротизм Добросовестность Экстраверсия Доброжелательность Открытость
#> 1 -0,22 -0,128 -1,327 -0,855 -1,61
#> 2 0,16 -0,466 -0,572 -0,072 -0,17
#> 3 0,62 -0,141 -0,043 -0,552 0,23
#> 4 -0,12 -0,058 -1,063 -0,091 -1,06
#> 5 -0,17 -0,460 -0,099 -0,712 -0,66 Сколько факторов следует сохранить в факторном анализе (FA)
При проведении факторного анализа (FA) часто требуется
указать сколько компонентов (или скрытых переменных) для
сохранить или извлечь.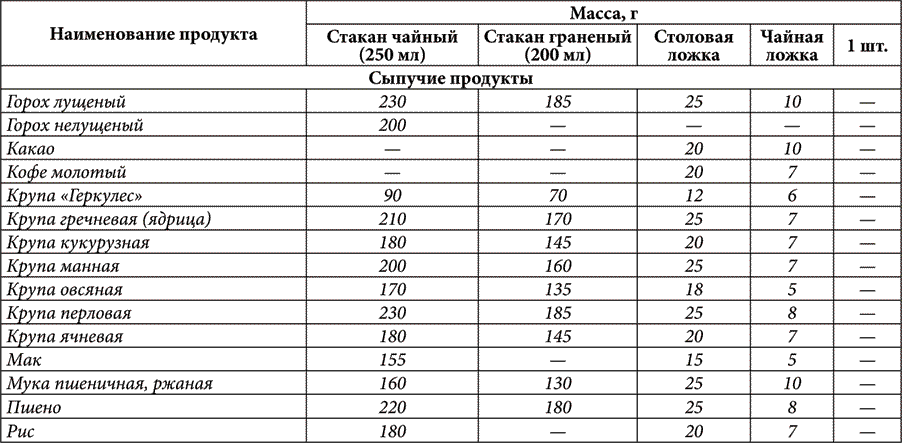 Это решение часто мотивируется или поддерживается
некоторые статистические показатели и процедуры, направленные на поиск оптимальных
количество факторов.
Это решение часто мотивируется или поддерживается
некоторые статистические показатели и процедуры, направленные на поиск оптимальных
количество факторов.
Существует огромное количество методов статистического учета этот вопрос, и они могут иногда давать очень разные результаты.
К сожалению, нет единого мнения о том, какой метод использовать, или что лучше.
Процедура согласования метода
Процедура согласования метода, впервые реализованная в психоанализе пакет (Makowski 2018), предлагает полагаться
на консенсусе методов, а не на одном методе в
конкретный.
Эту процедуру можно легко использовать с помощью n_factors() функция, повторно реализованная и улучшенная в параметры упаковка. Можно предоставить кадр данных, и функция будет выполнять большой
количество подпрограмм и вернуть оптимальное количество факторов на основе
более высокий консенсус.
n <- n_факторов(данные) н #> # Процедура согласования метода: #> #> Выбор 6 измерений поддерживается 3 (15,79%) методами из 19 (Оптимальные координаты, Параллельный анализ, Критерий Кайзера).
Интересно, что наименьшее количество факторов, которые предложить 6, что согласуется с новыми моделями личности (например, ГЕКСАКО).
Более подробную информацию, а также сводную таблицу можно получить по телефону следует:
as.data.frame(n) #> Семейство методов n_Factors #> 1 1 Коэффициент ускорения Scree #> 2 3 СПГ СПГ #> 3 4 бета Множественная_регрессия #> 4 4 Сложность VSS 1 VSS #> 5 5 Сложность VSS 2 VSS #> 6 5 КАРТА Велицера Velicers_MAP #> 7 6 Оптимальные координаты Осыпь #> 8 6 Параллельный анализ Осыпь #> 96 Критерий Кайзера Осыпь #> 10 7 t Множественная_регрессия #> 11 7 p Множественная_регрессия #> 12 7 Осыпь (R2) Осыпь_SE #> 13 8 Осыпь (SE) Осыпь_SE #> 14 8 БИК БИК #> 15 11 БИК (скорректированный) БИК #> 16 22 Бентлер Бентлер #> 17 24 Барлетт Барлетт #> 18 24 Андерсон Барлетт #> 1924 Лоули Барлетт резюме (сущ.) #> n_факторов n_методов #> 1 1 1 #> 2 3 1 #> 3 4 2 #> 4 5 2 #> 5 6 3 #> 6 7 3 #> 7 8 2 #> 8 11 1 #> 9 22 1 #> 10 24 3
Также можно получить график (пакет см. должен быть
загружено):
Подтверждающий факторный анализ (CFA)
Мы видели выше, что в то время как EFA с 5 скрытыми переменными работает отлично подходит для нашего набора данных, структура с 6 скрытыми факторами на самом деле может быть более подходящий. Как мы можем статистически протестировать , если это на самом деле так? Это можно сделать с помощью подтверждающего фактора . Анализ (CFA) (в отличие от Исследовательский FA), который объединяет факторный анализ с моделированием структурными уравнениями (СЭМ).
Однако для того, чтобы сделать это чисто, EFA должен быть независимый от CFA: факторная структура должна быть исследованы в «тренировочном» наборе , а затем проверены (или «подтверждено») в «тестовом» наборе .
Другими словами, набор данных, используемый для исследования и подтверждения
не должно быть одинаковым, стандарт, широко принятый в области
машинное обучение.
Разделить данные
Данные можно легко разделить на два набора с функция data_partition() , с помощью которой мы будем использовать 70%
образец в качестве обучения, а остальные в качестве теста.
# чтобы получить воспроизводимый результат, мы также установим здесь начальное значение, чтобы # порции данных используются каждый раз, когда мы запускаем следующий код разделы <- datawizard :: data_partition (данные, training_proportion = 0,7, seed = 111) обучение <- перегородки$p_0.7 test <- partitions$test
Создание структур CFA из моделей EFA
На следующем шаге мы запустим две модели EFA на обучающем наборе, указав 5 и 6 латентных факторов соответственно, что мы будем тогда трансформируются в структуры CFA.
structure_big5 <- psych::fa(обучение, nfactors = 5) %>% efa_to_cfa() Structure_big6 <- psych::fa(обучение, nfactors = 6) %>% efa_to_cfa() # Исследуйте, как выглядят модели структура_большой5 #> # Скрытые переменные #> MR2 =~ N1 + N2 + N3 + N4 + N5 + .row_id #> MR1 =~ E1 + E2 + E3 + E4 + E5 #> MR3 =~ C1 + C2 + C3 + C4 + C5 #> MR5 =~ A1 + A2 + A3 + A4 + A5 #> MR4 =~ O1 + O2 + O3 + O4 + O5 структура_большая6 #> # Скрытые переменные #> MR2 =~ N1 + N2 + N3 + N5 + .row_id #> MR3 =~ C1 + C2 + C3 + C4 + C5 #> MR1 =~ E1 + E2 + E4 + E5 + N4 + O4 #> MR5 =~ A1 + A2 + A3 + A4 + A5 #> MR4 =~ E3 + O1 + O2 + O3 #> MR6 =~ O5
Как мы видим, структура — это просто строка, кодирующая то, как переменные манифеста (наблюдаемые переменные) являются интегрированы в скрытых переменных .
Подгонка и сравнение моделей
Наконец, мы можем применить эту структуру к набору данных тестирования, используя lavaan package и сравните эти модели друг с другом.
другое:
библиотека (лаваан) библиотека (спектакль) big5 <- lavaan::cfa(structure_big5, data = test) big6 <- lavaan::cfa(structure_big6, data = test) производительность::compare_performance(большая5, большая6) #> # Сравнение индексов производительности моделей #> #> Имя | Модель | Чи2 | Chi2_df | р (Чи2) | Базовый уровень(325) | р (базовый уровень) | GFI | АГФИ | НФИ | НФИ | CFI | РМСЕА | РМСИ КИ | р (RMSEA) | РМР | СРМР | РФИ | ПНФИ | МФУ | РНИ | Логарифмическая вероятность | АПК (веса) | БИК (веса) | BIC_скорректированный #> ------------------------------------------------ -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------------- #> большой5 | лаван | 1366,793 | 289.
